TRANSFORM YOUR
HEALTHCARE OPERATIONS
With actionable analytics from your medical devices
Glassbeam’s platform of software and services deliver operational insights so you can achieve tangible results.
Measure and Optimize KPI’s
across your service line of medical assets.
THE IMAGING EQUIPMENT SERVICE CHECKLIST
As the healthcare industry shifts from fee to value-based care, imaging departments are being tasked to be more efficient while controlling costs.
Utilize the Imaging Equipment Service Checklist to help keep your vital pieces of equipment operating efficiently.

White Paper: Applying Machine Learning to Data Analytics
Utilizing machine data to reduce unplanned downtime and improve service operations efficiency.

Put Your Data to Work
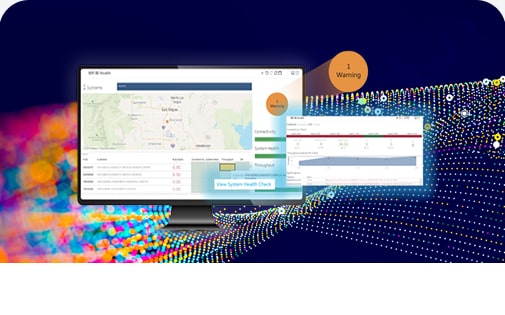
Drive Operational Efficiency
Consolidate and analyze equipment, staff performance and utilization data to anticipate interruptions and optimize workflow, schedules and staffing for effective and efficient service and clinical operations.

Manage Fleet-wide Utilization
Make your data actionable. Understand medical equipment utilization and opportunities for optimization. Glassbeam provides real-time insights to unlock greater efficiencies and access based on data patterns and outliers.

Minimize Unplanned Downtime
Anticipating required service instead of reacting to an emergency, dramatically improves system availability during operating hours – increasing system uptime, utilization and patient/staff satisfaction.
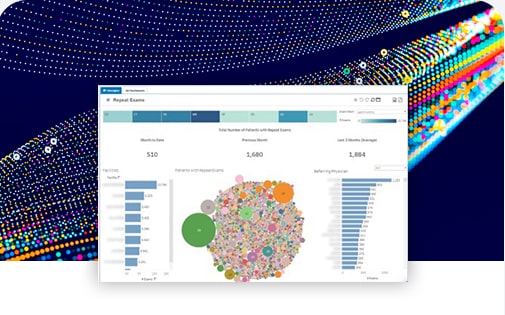
Elevate Business Intelligence
Deliver enterprise-wide impact through machine data insights. Analyze terabytes of log data for patterns to build correlations and share knowledge. Achieve breakthrough product and service excellence.
Solutions

Manufacturer Solutions
Unlock hidden value and extract insights from “multi-dimensional” machine data.
Learn MorePowered by Glassbeam
100X Increase your time to value by 100x.
Glassbeam’s patented platform ingests any complex log file and scales from gigaytes to terabytes of data per day. Our powerful proprietary language builds analytics from log data in a single step.
Actionable Insights Change the Way You Work
![]()
3,000+
Assets Connected (MR, CT, Cath Lab)
![]()
5M+
Exams (Annual)
![]()
300TB+
Terabytes (and increasing) Analytics Data Lake
Customer Results
![]()
Supporting over 250 Service Engineers with proactive alerts and IB analytics
![]()
Gained 70-80 hours of productive, revenue generating time per machine annually
![]()
Utilized proactive analytics to avoid 180 hours of unplanned downtime


